



从AI驱动到实时交互:虚拟数字人视频制作工具三大技术深度解析
在短视频与直播电商爆发式增长的今天,虚拟数字人技术正以“7×24小时无休、多语言适配、零边际成本”等优势重构内容生产逻辑。从本土化企业服务到全球化营销场景,工具的迭代方向逐渐清晰:降低制作门槛、强化交互能力、拓展应用边界
在短视频与直播电商爆发式增长的今天,虚拟数字人技术正以“7×24小时无休、多语言适配、零边际成本”等优势重构内容生产逻辑。从本土化企业服务到全球化营销场景,工具的迭代方向逐渐清晰:降低制作门槛、强化交互能力、拓展应用边界。本文将聚焦三款虚拟数字人视频制作工具,解析其技术架构与应用价值。
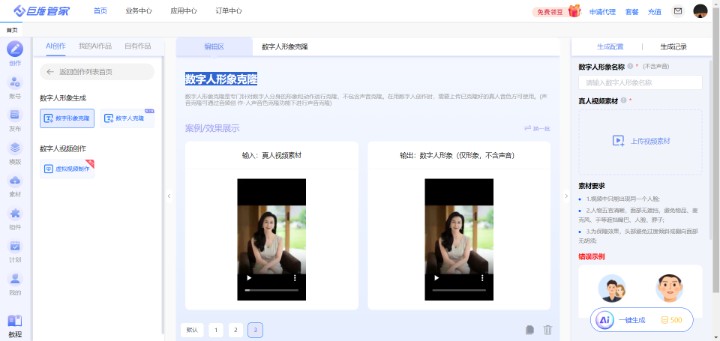
一、虚拟数字人视频制作工具(巨推)
核心定位:面向中小企业的全流程自动化视频生产平台,以“零剪辑基础+高性价比”切入市场。
技术亮点:
智能脚本生成引擎:基于NLP技术解析产品关键词,自动生成符合营销逻辑的解说文案。例如,某区域餐饮企业输入“新品小龙虾套餐”,系统可生成包含“痛点引入-产品卖点-促销信息”的30秒脚本,转化率提升22%。
多风格数字人库:提供50+虚拟形象,覆盖商务、休闲、专业等场景,支持服装、发型、表情的模块化调整。某教育机构使用“教师形象”数字人批量生成课程预告视频,品牌一致性提升40%。
一键多平台适配:内置抖音、快手、微信视频号等平台的格式参数,视频生成后自动调整分辨率、字幕位置与背景音乐风格。
应用场景:电商产品展示、本地化服务推广、知识付费课程预告。

典型案例:某连锁药店使用巨推管家生成“药品功效讲解”视频,通过更换背景与促销信息实现全国门店内容个性化,单条视频制作成本从2000元降至50元。
二、Hedra:照片驱动技术的“颠覆性创新”
核心定位:基于单张照片生成会说话虚拟人的国际化工具,主打“快速个性化”与“多语言支持”。
技术突破:
Character-3模型:通过扩散模型(Diffusion Model)与Transformer架构融合,实现口型同步误差<0.1秒、微表情自然度评分达4.2/5(用户调研数据)。
照片动态化引擎:用户上传正脸照片后,系统可生成3D可变形模型(3D Morphable Model),支持头部微动、眨眼、眉毛挑动等12种基础表情。
多语言语音合成:集成TTS(文本转语音)技术,支持英语、西班牙语、法语等30+语言,同一段内容可快速生成不同语言版本。
应用场景:跨国企业产品发布、培训教程本地化、社交媒体内容裂变。

技术延伸:Hedra已开放API接口,支持与Unity、Unreal Engine等游戏引擎集成,为虚拟演唱会、元宇宙活动提供动态角色解决方案。
三、Synthesia:企业级实时交互的“数字员工”生态
核心定位:面向大型企业的3D虚拟人实时交互平台,以“超写实建模+定制化LLM”构建品牌高端形象。
技术架构:
超写实3D建模:基于高精度扫描与PBR(物理渲染)技术,生成毛孔级细节的虚拟形象,支持4K/8K分辨率输出。
定制化大语言模型(LLM):企业可训练专属LLM,使其理解私有文档(如产品手册、财报数据),并实时回答观众提问。例如,某医疗设备公司创建“虚拟产品专家”,在展会中根据观众身份(医生/护士/采购)动态调整讲解深度。
实时数据连接:虚拟人可接入企业数据库,展示并分析最新业务指标。某金融机构使用Synthesia生成“虚拟分析师”,在路演中实时调取股票数据并生成可视化图表。
应用场景:高端销售演示、复杂产品培训、财务报告解读。

行业影响:Synthesia已与西门子、毕马威等跨国企业合作,将虚拟人应用于工业设备维护培训,通过实时交互降低现场操作风险。
技术趋势与选型建议
制作门槛持续降低:从专业工作室向智能手机应用演进,如Hedra支持手机摄像头实时捕捉表情。
交互能力从单向播放向智能对话升级:Synthesia的实时数据连接与LLM集成代表未来方向。
应用场景多元化:从营销视频扩展到培训、客服、娱乐等领域,如巨推管家已支持PPT自动生成讲解视频。
选型策略:
中小企业/个人创作者:优先选择巨推管家,平衡成本与效率;
跨国营销团队/教育机构:Hedra提供多语言支持与快速个性化能力;
大型企业/专业服务机构:Synthesia的实时交互与品牌高端形象塑造更具价值。
虚拟数字人不是“万能药”,但作为数字内容生态的新生力量,它正为企业内容创作与客户互动开辟令人兴奋的可能性。未来12-18个月,随着生成式AI与实时渲染技术的进步,我们或将见证“照片级实时虚拟人”的普及——制作成本进一步下降,表现力更加接近真人,而交互能力将成为核心竞争壁垒。